爬虫
 前置知识:Web, Python
前置知识:Web, Python
 讲师:刘铠铭 @kaiming
讲师:刘铠铭 @kaiming
 日期:8 月 3 日星期四
日期:8 月 3 日星期四
 DDL: 8 月 15 日星期二 23:59
DDL: 8 月 15 日星期二 23:59
 课程回放
课程回放
 作业
作业
通过学习本课程,你将有能力自行编写一些爬虫工具来辅助完成简单的任务(例如批量下载网络学堂文件,大批量下载网站检索信息,下载 Bilibili 视频等),你也有可能初步了解 Scrapy 等更高级的爬虫框架,了解如何应对现代网络中对爬虫常见防范手段,以满足更进阶的需求。
一、什么是爬虫
不考虑复杂的内容,我们可以简单的将“上网”概括为“浏览器向服务器按照用户意愿发送一系列请求,并将服务器的响应呈现给用户“的过程。而爬虫便是一种可以模拟网页浏览器向网站发送、处理请求的自动化脚本,帮助我们获得服务器的数据,进而用于其他需求。
那么爬虫可以做什么呢?可以认为一切与网络请求相关的内容爬虫都可以按照我们的需要进行处理。
二、课前准备
1. 预备知识
我们期待您已经掌握了 Python 的使用,了解了 Web 的基本知识,如果您对这两方面有疑惑,可以参考:
HTTP 基本知识:
Route yourself in XML:
2. 环境准备
请保存下面的 requirements.txt 并执行:
| requirements.txt |
|---|
| beautifulsoup4
requests
lxml
tqdm
notebook
jupyter
webdriver-manager
selenium
scrapy
|
| conda create -n crawler python=3.10
conda activate crawler
pip install -r requirements.txt
|
三、如何构建爬虫
代码构建过程还请参考回放。
1. 网络请求分析
构建爬虫的关键在于分析服务器请求,分析我们期望获得的数据在哪个或哪些请求中,进而构建“API Chains”。
网络请求的响应往往有三种类型:
- JSON
- HTML
- 二进制文件
对于 JSON,我们直接使用 json 分析即可;对于 HTML,我们则需要使用 BeautifulSoup4 搭配 HTML 解析器进行分析;对于二进制文件,我们可以直接保存。
之后我们将通过对 知乎 的爬取实践来熟悉构建爬虫的整个流程。
2. 爬取知乎首页
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30 | import requests
from bs4 import BeautifulSoup as BS
import json
from typing import List
def get_zhihu_hot_urls() -> List[str]:
"""
Get the hot urls list of zhihu
Returns:
The hot urls list of zhihu
"""
url = "https://www.zhihu.com/hot"
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Safari/605.1.15",
}
with open("config.json", "r") as f:
config = json.load(f)
headers["cookie"] = config["cookie"]
resp = requests.get(url=url, headers=headers)
soup = BS(resp.text, "lxml")
hot_list = []
for item in soup.find_all("div", class_="HotItem-content"):
hot_list.append(item.find("a")["href"])
return hot_list
hot_urls = get_zhihu_hot_urls()
hot_urls
|
3. 爬取某项问题下的所有回答
3.1 API 分析
请参考回放
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46 | import requests
import json
from typing import List, Dict
from bs4 import BeautifulSoup as BS
import re
def get_all_answers(qid: str) -> List[Dict]:
"""
Get all answers of a question
Args:
qid: The id of the question
Returns:
The list of all answers
"""
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Safari/605.1.15",
}
with open("config.json", "r") as f:
config = json.load(f)
headers["cookie"] = config["cookie"]
url = f"https://www.zhihu.com/question/{qid}"
resp = requests.get(url=url, headers=headers)
soup = BS(resp.text, "lxml")
sessionId = soup.find("script", id="js-initialData").text
sessionId = re.findall(r'"sessionId":"(.*?)"', sessionId)[0]
url = f"https://www.zhihu.com/api/v4/questions/{qid}/feeds?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Creaction_instruction%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset=0&order=default&platform=desktop&session_id={sessionId}"
answers = []
while True:
resp = requests.get(url=url, headers=headers)
data = resp.json()["data"]
answers.extend(data)
if resp.json()["paging"]["is_end"]:
break
url = resp.json()["paging"]["next"]
return answers
data = get_all_answers("613681273")
authors = [
d["target"]["author"]["name"] for d in data if d["target"]["type"] == "answer"
]
print(authors)
|
3.2 Selenium + WebDriver 模拟浏览器操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47 | import json
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait as wdw
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options as ChromeOptions
import selenium
chrome_options = ChromeOptions()
chrome_options.binary_location = "/Applications/Google Chrome.app/Contents/MacOS/Google Chrome"
driver = selenium.webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=chrome_options)
driver.get(f"https://www.zhihu.com/question/613681273")
# 尝试输入账号密码登录功能
with open("config.json", "r") as f:
config = json.load(f)
username = driver.find_element(By.XPATH, '/html/body/div[5]/div/div/div/div[2]/div/div/div/div[2]/div[1]/div[2]/div/div[1]/div/form/div[2]/div[2]/label/input')
username.send_keys(config["username"])
password = driver.find_element(By.XPATH, '/html/body/div[5]/div/div/div/div[2]/div/div/div/div[2]/div[1]/div[2]/div/div[1]/div/form/div[3]/div/label')
password.send_keys(config["password"])
login = driver.find_element(By.XPATH, '/html/body/div[5]/div/div/div/div[2]/div/div/div/div[2]/div[1]/div[2]/div/div[1]/div/form/button')
login.click()
# 关闭窗口
wdw(driver, 10).until(EC.presence_of_element_located((By.XPATH, '/html/body/div[5]/div/div/div/div[2]/button')))
button_quit = driver.find_element(By.XPATH, '/html/body/div[5]/div/div/div/div[2]/button')
button_quit.click()
while True:
driver.execute_script("window.scrollBy(0, -10);")
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
if driver.find_elements(By.XPATH, '//*[@id="root"]/div/main/div/div/div[3]/div[1]/div/div[2]/a/button'):
break
authors = [item.text for item in driver.find_elements(By.CLASS_NAME, 'UserLink-link')]
authors = [item for item in authors if item != '']
print(authors)
driver.quit()
|
除去上述内容外,Selenium 还有很多有用的方法,包含但不限于:
- Action 链;
- 键盘组合键;
- 几乎一切你在使用浏览器中会用到的操作;
- ...
四、Scrapy 入门
Scrapy (/ˈskreɪpaɪ/) is an application framework for crawling web sites and extracting structured data which can be used for a wide range of useful applications, like data mining, information processing or historical archival.
Even though Scrapy was originally designed for web scraping, it can also be used to extract data using APIs (such as Amazon Associates Web Services) or as a general purpose web crawler.
我们在之前使用的 BeautifulSoup4,lxml 等都只是构建爬虫过程中使用的工具,而 Scrapy 则是构建爬虫的框架。Scrapy 之于爬虫就如同 Django 之于后端,React 之于前端,其为构建爬虫预先准备了大量丰富的方法。
Scrapy 的优越性太多了,可以直接参考 官网 的描述。
1. Architecture & Components
Scrapy 的架构如下:
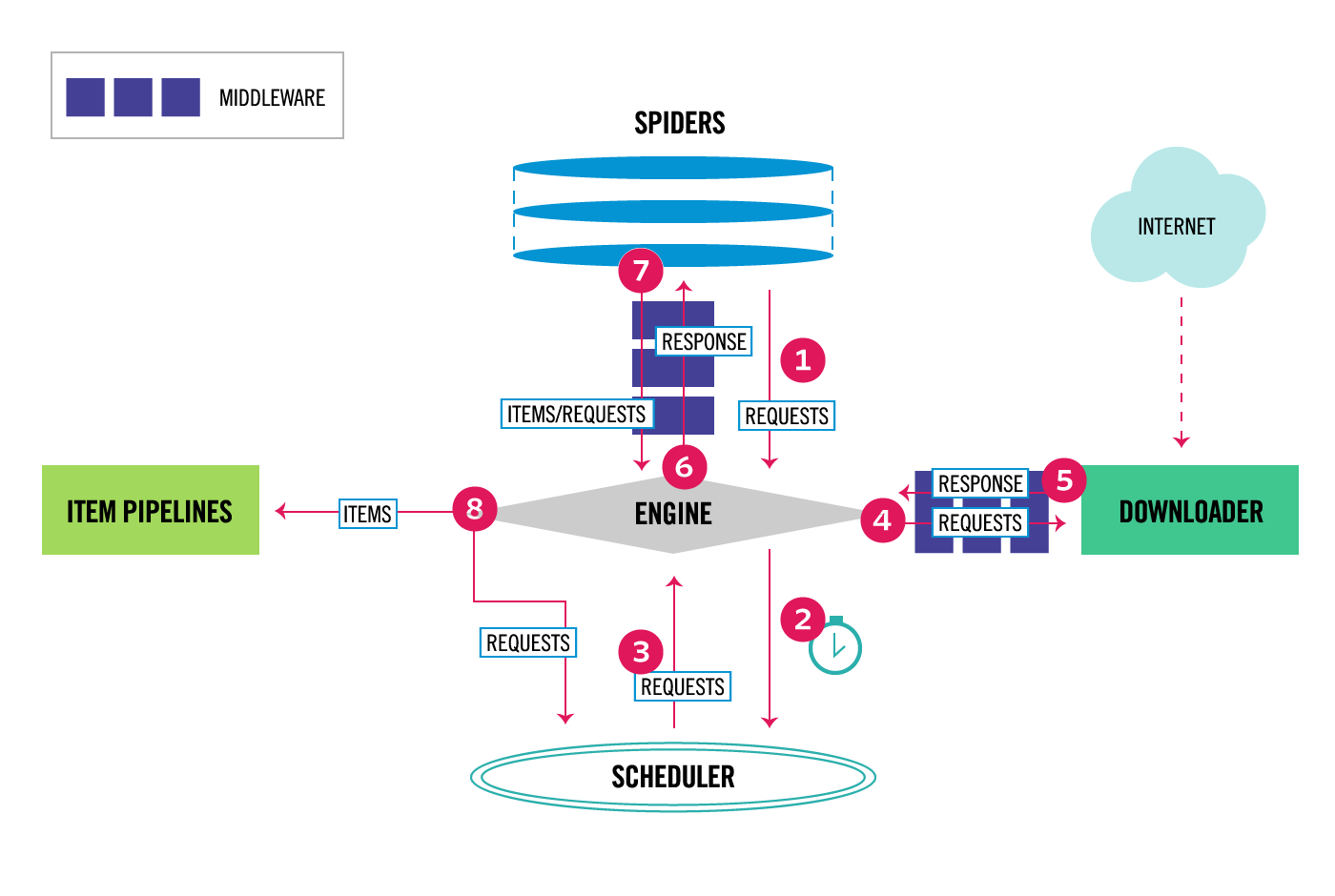
框架的组件包括:
1. Scrapy Engine: 调节其余各组件,控制数据流;
2. Schedule: 优先队列,调度 requests;
3. Downloader: 下载器,即向网络发送请求;
4. Spider: 自定义类,主类,解析 responses,构建 items 等;
5. Item Pipeline: 在 Spider 生成 Item 后,在该组件中执行后续工作,例如验证,加入数据库等;
6. Downloader middlewares: 中间件;
7. Spider middlewares: 中间件
2. A Simple Example
让我们用 Scrapy 框架来实现知乎爬虫:
| conda activate crawler
scrapy startproject zhihu
cd zhihu
scrapy genspider hotpage zhihu.com/hot
|
之后的构建就可以听回放喽!
五、作业
ddl:2023.08.15
当你遇到困难时,请随时在群中询问,你也可以参考 参考实现 中的实现。
只需在以下任务选择列表中选择任意一个任务的基本功能完成即可获得满分。
1. 提交方式
请将你的代码上传至 TsinghuaGit,要求仓库中必须包含代码的使用说明,请将其写在 readme.md 中。之后请将你的姓名+学号+仓库链接提交至 该 git 仓库的 issue 中,如担心隐私泄漏,可通过其他方式告知讲师。
2. 任务列表
选一做即可。
2.1 清华云盘爬虫
Input:某个清华云盘共享文件夹链接,例如 https://cloud.tsinghua.edu.cn/d/ba64d0debd0e4ad4bf92/;
Output:下载该文件夹内所有文件,且按照原文件的组织方式组织文件。
2.2 清华大学教参平台爬虫
Input:某本教参详情页的 URL,例如 http://reserves.lib.tsinghua.edu.cn/Search/BookDetail?bookId=11ad92b1-d4f1-4ea9-8d2c-310640ba96b1;
Output:包含该本书的所有图片的 PDF。
2.3 Bilibili 网页端视频下载
Input:某个视频的 BV 号,例如 BV1C14y1z7xh;
Output:下载该视频,需要支持下载 1080P (若有),可以不合并视频 & 音频。
六、写在最后
当你进行商业用途或可能占用对方服务器大量资源的行为时,请优先查阅 .../robots.txt 文件。
爬虫只是用来获取数据的途径,而如何解读数据才能体现其核心价值。
最后更新:
2023年8月3日