数据库 & SQL
 前置知识:无
前置知识:无
 讲师:刘铠铭 @kaiming
讲师:刘铠铭 @kaiming
 日期:7 月 14 日星期五
日期:7 月 14 日星期五
在过去的一年中,我们接触的往往只有少量、临时的数据,因此数据可以以简单的文件形式直接进行存储。但随着数据的迅速膨胀,以文件存储数据的方式存在诸如可扩展性差、无法保证数据的完整性、一致性以及安全性等问题,因此数据库管理系统应运而生。而 SQL 作为当今管理数据库最常用的语言,也值得我们进行学习。
通过本节课,你将了解数据库技术的相关知识,并初步掌握利用 SQL 进行数据库管理与查询的基本方法。在小学期与软件工程课程中,本节课的所学也将得以应用。
 课程回放
课程回放
一、课程概述
1. 为什么需要数据库?
日常生活中我们离不开数据,在过去我们保存数据最简单的方法是将数据写入文件中,例如将学生成绩记录在 Excel 表格中。然而在开发环境中,我们往往会面临成千上万的数据,此时考虑数据存储时便需要考虑到效率、便捷性、是否方便复用等问题。
在此背景下,数据库作为一种专门管理数据的软件便出现了。应用程序只需调用数据库软件提供的 API 接口便可以实现数据的读写,而无需在意数据在文件中如何存储以及如何索引。同学们可在“数据库系统概论”课程深入学习数据的存储方式与检索方式。
2. 关系型数据库

关系型数据库是建立在关系模型上的,其将数据看作若干个二维表格,我们可以将其看作一个个 Excel 表。其中:
- 表的每一行称为一条记录(Record),即一条完整的数据;
- 表的每一列称为一个字段(Column),代表一条记录的某个属性;
与 Excel 不同的是,在关系型数据库中表与表之间可以存在“一对多”,“多对一”以及“一对一”的关系。例如我们考虑选课问题:
- 每位同学拥有
[sid, name, major] 三个属性;
- 每个课程拥有
[cid, title, credit, time, grade] 五个属性;
倘若用一张 Excel 表格来存储,假设有 10 个学生,每个学生均选择了 10 门相同的课程,那么 Excel 表格的数据存储量约为 (3 + 5) \times 10 \times 10 = 800,其中存在大量冗余;而在关系型数据库中,我们可以设计三张数据表(现阶段我们只需考虑 Field 与 Type 两列,每个 Field 表示一个字段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33 | mysql> DESC Students;
+-------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| sid | char(10) | NO | UNI | NULL | |
| name | varchar(255) | NO | | NULL | |
| major | varchar(255) | NO | | NULL | |
+-------+--------------+------+-----+---------+----------------+
4 rows in set (0.00 sec)
mysql> DESC Courses;
+--------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+--------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| cid | varchar(8) | NO | UNI | NULL | |
| title | varchar(255) | NO | | NULL | |
| credit | int | NO | | NULL | |
| time | varchar(255) | YES | | NULL | |
+--------+--------------+------+-----+---------+----------------+
6 rows in set (0.00 sec)
mysql> DESC Association;
+------------+---------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+---------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| student_id | int | YES | MUL | NULL | |
| course_id | int | YES | MUL | NULL | |
| grade | char(2) | YES | | NULL | |
+------------+---------+------+-----+---------+----------------+
4 rows in set (0.00 sec)
|
此时我们只需为每名同学和每个课程建立一行信息,并在 Association 中添加其关系即可,因此数据存储量约为 4 \times 10 + 5 \times 10 + 4 \times 10 \times 10 = 490。
该问题在 Association 中通过两个外键来建立学生和课程之间的关联,展示了关系型数据库中的基本应用(外键将在之后学习)。在本节课中,我们将学习如何在这些数据表上进行所需操作。
二、课前准备
在本课程中,我们将使用 MySQL 这一关系型数据库管理系统。
1. 环境配置
1.1 Ubuntu / Ubuntu(WSL2)
必选项
直接使用 apt 包管理器进行安装即可:
| sudo apt update
sudo apt upgrade
sudo apt install mysql-server
|
之后检验是否成功安装:
若该步未成功运行,你可能需要使用 service/systemctl 来启动 mysql service。
可选项
注:尽管该步骤并非必要,但建议你尝试手动配置以体验生产环境。
在开始前,请首先设置 root 用户密码:
| sudo mysql
mysql> ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password by 'YourPassword';
# 在后续操作时,即可通过 mysql -u root -p 以 root 身份登录
|
在生产环境中,为了提高 MySQL 的安全性,我们有必要进行安全配置,可使用如下指令进行操作:
| sudo mysql_secure_installation
|
该步骤中将进行如下操作(输入指令后即可明白一切):
- 移除不需要的默认用户(例如 root);
- 为 root 用户设置密码,确保只有授权用户可以访问数据库;
- MySQL 在安装后会自动创建一个无用户名无密码的匿名用户(Anonymous Account),默认情况下 MySQL 允许匿名用户连接到数据库服务器,以方便新用户快速上手。然而在生产环境中攻击者可能利用这个漏洞来尝试访问数据库并进行恶意操作,因此我们可以在该步骤中删除匿名用户;
- 禁止远程 root 登录,限制其只能在本地访问;
- 删除测试数据库:删除 MySQL 安装过程中创建的一些测试数据库。
1.2 Windows & Mac
注:未测试
- 在 官网 安装 MySQL Installer,手动安装即可。
- 可参考 网络教程。
2. 用户设置
您无需特别在意本节代码含义,如希望提前研究可参考:
2.1 创建用户
首先我们创建一个 admin 用户:
| sudo mysql # 以 root 用户登录
# or
mysql -u root -p # 以 root 用户登录
|
| mysql> CREATE USER 'admin'@'%' IDENTIFIED BY '123456';
Query OK, 0 rows affected (0.01 sec)
|
表示允许用户 admin 从任意 IP 以密码 123456 登录。
2.2 权限分配
新创建的用户是没有任何权限的(USAGE 表示没有任何权限),我们可以使用 SHOW GRANTS 进行查询:
| mysql> SHOW GRANTS FOR 'admin'@'%';
+-----------------------------------+
| Grants for admin@% |
+-----------------------------------+
| GRANT USAGE ON *.* TO `admin`@`%` |
+-----------------------------------+
1 row in set (0.00 sec)
|
为方便后续操作,我们为 admin 添加所有数据库和数据表的所有权限:
| mysql> GRANT ALL PRIVILEGES ON *.* TO 'admin'@'%';
Query OK, 0 rows affected (0.02 sec)
|
2.3 用户登录
使用 exit 语句或者使用 Ctrl-D 即可退出登录:
用命令行登录 admin:
| mysql -u admin -p # 之后输入密码即可登录
|
或者使用
也可直接登录,但是会在 shell 的历史记录中留下密码的明文记录,因此不推荐在服务器中使用:
| cat .bash_history # .zsh_history 等
|
三、SQL 入门
1. 基本概念
SQL 语言特性:
| mysql> SELECT 1 + "1";
+---------+
| 1 + "1" |
+---------+
| 2 |
+---------+
1 row in set (0.00 sec)
|
- 关键字不区分大小写;而数据库名,表名,字段名等区分大小写。如:
| mysql> cReAtE dAtAbAsE hello;
Query OK, 1 row affected (0.01 sec)
mysql> cReAtE dAtAbAsE Hello;
Query OK, 1 row affected (0.02 sec)
|
分别创建了 hello 和 Hello 两个数据库。
当出现数据库名,表名,字段名与关键字重复时,需要使用反引号`将其包裹。为了美观与可读性,建议关键字统一使用大写表示。
2. 数据类型
由于数据库的核心便是“数据”,不同的数据类型会影响数据的存储方式与检索方式,因此为每张表的字段选择最合适的数据类型是十分有必要的。MySQL 支持的类型大致可以分为数值、日期/时间和字符串三类,在此仅列举常用的类型:
-
数值类型
-
INT:4 bytes,[-2^{31},2^{31}-1]
-
BIGINT:8 bytes,[-2^{63},2^{63}-1]
-
FLOAT:4 bytes
-
DOUBLE:8 bytes
-
可使用 UNSIGEND 关键字来表示无符号类型,以表示更大的范围,例如:
| CREATE TABLE your_table (
your_column INT UNSIGNED
);
|
-
字符串类型
-
CHAR:定长字符串,256 bytes,长度取值范围为 [0,255] 个字符;
-
VARCHAR:变长字符串,长度取值范围为 [0,65535] 个字符;
-
日期和时间类型
-
TIMESTAMP:时间戳,形式为 YYYY-MM-DD hh:mm:ss,4 bytes,范围为 [1970-01-01 00:00:01 \ \mathrm{UTC},2038-01-19 03:14:07 \ \mathrm{UTC}],常见的写法有:
| CREATE TABLE your_table (
...
event_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
|
特别的,NULL 表示空值(与 0 和 '' 作区分)。但字段在设置时应尽量“避免允许为 NULL”,这样可以简化查询条件,加快查询速度,也利于应用程序读取数据后无需判断其是否为 NULL。
3. 主键,外键与索引
3.1 主键
关系型数据库要求同一张数据表中的任意两条记录不得重复,要求能通过某字段唯一区分出不同的记录,该字段称为主键。常见的可作为主键字段的类型有:
- 自增整数类型;
- 全局唯一 GUID 类型:使用 GUID 算法生成一个全局唯一的字符串。
注意,尽管只要我们保证某一字段不重复,便可以将其作为主键,但我们不推荐将业务相关的字段作为主键,这主要时防止当其需要变更时出现关系上的错误。
例如,若我们将课程的课程号 cid 作为主键,尽管其是唯一的,但假如课程的课程号发生改变,或者其位数需要增加,那么在修改时我们还必须同时修改 Association 表中的内容,并且要确保没有重复的值或者确保在迁移数据时处理了重复值的情况。
除去将单一字段作为主键外,我们还可以使用联合主键,即用多个字段同时唯一确定某一条记录。
3.2 外键
与主键类似,外键也是一种约束性质,在 Association 数据表中,student_id 和 course_id 分别外链到 Students 和 Courses 两张数据表中的 id 属性。通过定义外键约束,关系型数据库可以保证无法插入无效的数据,即无法插入在 Students 表或 Courses 表中不存在的 id号。
然而,外键约束会降低数据库的性能,所以在应用程序可以保证逻辑正确性的前提下,我们可以不设置外键约束。此时 student_id 和 course_id 只是两个普通的字段,但是其在使用逻辑上起到了外键的作用。
3.3 索引
在汉语词典中,我们可以按照拼音、笔画、偏旁部首等方式进行索引,通过这些方式进行索引通常可以获得更快的检索速度。
“索引”这一概念对于数据表也是这样。倘若我们为某一个字段建立了索引(为某种方式在词典中建立了目录),那么在通过这一字段进行检索时便通常可以获得更快的查询速度。关系型数据库会自动为主键建立索引,由于主键会保证绝对唯一,因此采用主键索引往往是效率最高的。对于其他字段,当其重复项不多且常常依赖其进行查询时,我们也可以考虑为其创建索引,例如 Studens 表中的 sid 和 Courses 表中的 cid。
然而,由于在插入、更新和删除记录时,需要同时修改索引,因此索引会减慢插入、更新和删除记录的速度。
4. 数据库和数据表操作
4.1 CREATE
创建新的数据库,然后使用它:
| CREATE DATABASE summer;
USE summer;
|
创建课程概述中所述问题所需的数据表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23 | CREATE TABLE Students (
id INT AUTO_INCREMENT PRIMARY KEY,
sid CHAR(10) NOT NULL UNIQUE,
name VARCHAR(255) NOT NULL,
major VARCHAR(255) NOT NULL
);
CREATE TABLE Courses (
id INT AUTO_INCREMENT PRIMARY KEY,
cid VARCHAR(8) NOT NULL UNIQUE,
title VARCHAR(255) NOT NULL,
credit INT NOT NULL,
time VARCHAR(255)
);
CREATE TABLE Association (
id INT AUTO_INCREMENT PRIMARY KEY,
student_id INT,
course_id INT,
grade CHAR(2),
CONSTRAINT fk_student_id FOREIGN KEY (student_id) REFERENCES Students(id),
CONSTRAINT fk_course_id FOREIGN KEY (course_id) REFERENCES Courses(id)
);
|
查看当前数据库中的所有数据表:
可以用 DESC (Describe)语句查看表的字段情况:
4.2 ALTER
ALTER 语句用于给数据表添加、删除字段,修改字段的类型或属性,例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14 | ALTER TABLE Students
ADD gender VARCHAR(10); -- 添加字段
ALTER TABLE Students
DROP COLUMN gender; -- 删除字段
ALTER TABLE Students
MODIFY COLUMN sid CHAR(20); -- 修改字段
ALTER TABLE Students
ADD INDEX idx_sid (sid); -- 建立索引
ALTER TABLE Association
DROP FOREIGN KEY fk_student_id; -- 删除外键
|
4.3 DROP
删表与删库:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24 | mysql> DROP TABLE Students;
Query OK, 0 rows affected (0.02 sec)
mysql> DROP DATABASE summer;
Query OK, 2 rows affected (0.06 sec)
mysql> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.01 sec)
mysql> SELECT DATABASE(); -- 查看当前位于的数据库名称,`NULL` 表示没有选择任何数据集
+------------+
| DATABASE() |
+------------+
| NULL |
+------------+
1 row in set (0.00 sec)
|
5. CRUD
In computer programming, create, read, update, and delete (CRUD) are the four basic operations of persistent storage.
| CRUD |
SQL |
| Create |
INSERT |
| Read |
SELECT |
| Update |
UPDATE |
| Delete |
DELETE |
5.1 INSERT
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43 | INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[(col_name [, col_name] ...)]
{ {VALUES | VALUE} (value_list) [, (value_list)] ... }
[AS row_alias[(col_alias [, col_alias] ...)]]
[ON DUPLICATE KEY UPDATE assignment_list]
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
SET assignment_list
[AS row_alias[(col_alias [, col_alias] ...)]]
[ON DUPLICATE KEY UPDATE assignment_list]
INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[(col_name [, col_name] ...)]
{ SELECT ...
| TABLE table_name
| VALUES row_constructor_list
}
[ON DUPLICATE KEY UPDATE assignment_list]
value:
{expr | DEFAULT}
value_list:
value [, value] ...
row_constructor_list:
ROW(value_list)[, ROW(value_list)][, ...]
assignment:
col_name =
value
| [row_alias.]col_name
| [tbl_name.]col_name
| [row_alias.]col_alias
assignment_list:
assignment [, assignment] ...
|
假设我们已经创建了上述三张表,那么我们便可以使用 INSERT INTO 来向这些空表中插入数据:
| INSERT INTO Students VALUES (0, '2023000000', 'Alice', 'Computer Science');
|
也可以指定字段名:
| INSERT INTO Students (sid, name, major)
VALUES ('2023000002', 'Bob', 'EE');
|
没有指定值得字段将默认被分配 NULL 或 DEFAULT 值,如果字段又 NOT NULL 属性,则会引发错误。
也可以一次性插入多条记录:
| INSERT INTO Students (sid, name, major) VALUES
('2023000003', 'Carol', 'CS'),
('2023000004', 'Eve', 'CS');
|
为了我们后续的学习,我们可以插入一些预置:
| mysql> DROP TABLE Association;
mysql> TRUNCATE TABLE Students; -- 清空 Students 数据表,重置自增变量
mysql> exit;
|
在 shell 中执行:
| curl -fsSL https://cloud.tsinghua.edu.cn/f/b8d1f041d9174890bc60/\?dl\=1 -o summer.sql
|
然后进入 MySQL 命令行:
| mysql> USE summer;
mysql> source <file path>/summer.sql;
|
若执行
| mysql> SELECT COUNT(*) from Students;
+----------+
| COUNT(*) |
+----------+
| 50 |
+----------+
1 row in set (0.00 sec)
|
则说明导入成功。
5.2 SELECT
SELECT 是 MySQL 中的核心操作,首先我们来看 SELECT 的全部语法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32 | SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr] ...
[into_option]
[FROM table_references
[PARTITION partition_list]]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}, ... [WITH ROLLUP]]
[HAVING where_condition]
[WINDOW window_name AS (window_spec)
[, window_name AS (window_spec)] ...]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[into_option]
[FOR {UPDATE | SHARE}
[OF tbl_name [, tbl_name] ...]
[NOWAIT | SKIP LOCKED]
| LOCK IN SHARE MODE]
[into_option]
into_option: {
INTO OUTFILE 'file_name'
[CHARACTER SET charset_name]
export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name] ...
}
|
其中必要的只有 SELECT select_option 这一项,本节将就其中重要的选项进行讲解,若感兴趣可以一一查找。
5.2.1 基本操作
暴力地取出整张表:
在生产环境中使用该操作应谨慎,因为若记录特别多或某个字段特别长,这将消耗大量的网络传输和内存消耗,且可能出现数据暴露等问题。
查看指定的列:
| SELECT id, title, credit FROM Courses;
|
5.2.2 WHERE
我们可以使用 WHERE 进行筛选,例如查找所有开课时间为 2023-Spring 且学分大于 1 的课程:
| SELECT * FROM Courses WHERE time = '2023-Spring' AND credit > 1;
|
5.2.2.1 IN
在使用 WHERE 进行过滤时我们可以指定范围,如我们只想查询学分为 1 或 2 的课程:
| SELECT * FROM Courses WHERE credit IN (1, 2);
|
5.2.2.2 LIKE
可以使用 LIKE 进行模糊匹配,例如查找所有上课时间在 2022 年的课程:
| SELECT * FROM Courses WHERE time LIKE '2022%';
|
更多例子可以参见 SQL LIKE Operator (w3schools.com), SQL Wildcard Characters (w3schools.com)
5.2.2.3 NULL
由前所述,没有被分配值且没有默认值得字段在插入时会被分配 NULL 这个空值来表示记录中的某个字段没有数据,可以使用 ISNULL 来进行判断。如找出所有没有登记分数得选课记录:
| SELECT * FROM Association WHERE ISNULL(grade);
|
注意不能使用 grade = NULL 来判断是否为 NULL:
| mysql> SELECT * FROM Association WHERE grade = NULL;
Empty set (0.00 sec)
|
判断非空可以使用 NOT INSULL(<column_name>),如
| SELECT * FROM Association WHERE NOT ISNULL(grade);
|
而不是
| mysql> SELECT * FROM Association WHERE grade <> NULL;
Empty set (0.00 sec)
|
5.2.3 COUNT, MAX, MIN, SUM, AVG
可以查看共有多少条记录:
| SELECT COUNT(*) FROM Association;
|
类似的可以查看最大值,最小值,合,平均值,例如计算所有课程得平均学分:
| SELECT AVG(credit) FROM Courses;
|
5.2.4 GROUP BY
我们想看看在所有课程中不同的等级分别由多少人:
| SELECT grade, COUNT(*) FROM Association GROUP BY grade;
|
在查询中,我们可以给字段、表、和查询赋予一个临时的,仅在这次查询中使用的名称。
例如对于上面的查询,我们给 COUNT(*) 一个临时名称 student_count:
| SELECT grade, COUNT(*) student_count FROM Association GROUP BY grade;
|
在 GROUP BY 时,你通常不能选择没有受到 GROUP BY 修饰的字段,例如如下查询:
| mysql> SELECT student_id, grade, COUNT(*) student_count FROM Association GROUP BY grade;
ERROR 1055 (42000): Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'summer.Association.student_id' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
|
这是因为同一个 grade 可能包括多个 student_id,因此其定义不良好。
当我们希望选择其他列时,可以考虑使用 JOIN 选项。
5.2.5 HAVING
可能想要对聚合算子的结果进行过滤,比如试图选出大于 20 个人的等级:
| mysql> SELECT grade, COUNT(*) FROM Association GROUP BY grade WHERE COUNT(*) > 20;
ERROR 1111 (HY000): Invalid use of group function
|
此时我们可以用 HAVING 来过滤聚合算子的结果:
| SELECT grade, COUNT(*) FROM Association GROUP BY grade HAVING COUNT(*) > 20;
|
5.2.6 DISTINCT
当我们希望查询的结果中没有重复值时,可以使用 DISDINCT,例如等级的种类:
| SELECT DISTINCT grade FROM Association;
|
5.2.7 ORDER BY
当我们希望对查询结果排序时,可以使用 ORDER BY,例如对课程的学分进行排序:
| SELECT title, credit FROM Courses ORDER BY credit;
|
默认结果为升序,我们也可以规定降序:
| SELECT title, credit FROM Courses ORDER BY credit DESC;
|
我们也可以对多个字段排序,如优先按照学分降序,再按照课程名升序:
| SELECT title, credit FROM Courses ORDER BY credit DESC, title ASC;
|
也可以对 GROUP BY 的结果排序,例如按照获得某等级的学生个数排升序:
| SELECT grade, COUNT(*) student_count FROM Association GROUP BY grade ORDER BY student_count;
|
5.2.8 LIMIT
LIMIT 可以对结果指定偏移与范围,比如我们查找学号最小的 10 位学生:
| SELECT sid, name FROM Students ORDER BY sid LIMIT 10;
|
假如这样的查询是要分给一个后端,每页10个,我们想要去查第 4 页的结果:
| SELECT sid, name FROM Students ORDER BY sid LIMIT 30, 10;
|
表示从第 30 位学生开始,查询 10 条记录。
5.2.9 Sub Query
对于每次查询得到的结果集合,我们可以将其视为一个临时的数据表,可以(必须)对他起一个临时名称(别名)后继续进行 SELECT 等操作。而这样嵌套在查询中的查询称为 Sub Query,具有很强的表达能力,而且十分符合人类的思维直觉。
例如我们希望查询选课超过了平均值的学生的选课记录,可以将查询分为 3 步:
- 查询学生选课的数量:
| SELECT COUNT(*) cnt FROM Association GROUP BY student_id;
|
- 对这些数量求平均:
| SELECT AVG(q1.cnt) FROM (
SELECT COUNT(*) cnt FROM Association GROUP BY student_id
) q1;
|
其中 q1 是对第一个子查询的别名
- 从
Association 表中筛选出相应的记录:
| SELECT student_id, COUNT(*) cnt FROM Association GROUP BY student_id HAVING cnt > (
SELECT AVG(q1.cnt) FROM (
SELECT COUNT(*) cnt FROM Association GROUP BY student_id
) q1
);
|
子查询也可以用在 WHERE 语句中,例如希望查询选课数量排前 10 名学生的全部信息,可以将查询分为 3 步:
- 从
Association 表中查出选课数量排前 10 名的学生的 id:
| SELECT student_id, COUNT(*) cnt
FROM Association
GROUP BY student_id
ORDER BY cnt DESC
LIMIT 10;
|
- 从中选出
id:
| SELECT student_id FROM (
SELECT student_id, COUNT(*) cnt
FROM Association
GROUP BY student_id
ORDER BY cnt DESC
LIMIT 10
) top_s;
|
- 从
Students 表中查出这些同学的信息:
| SELECT * FROM Students WHERE id in (
SELECT top_s.student_id FROM (
SELECT student_id, COUNT(*) cnt
FROM Association
GROUP BY student_id
ORDER BY cnt DESC
LIMIT 10
) top_s
);
|
5.2.10 JOIN
JOIN 是我们可以对多个表的结果按照某些列的约束关系进行拼接,常见的模式由:
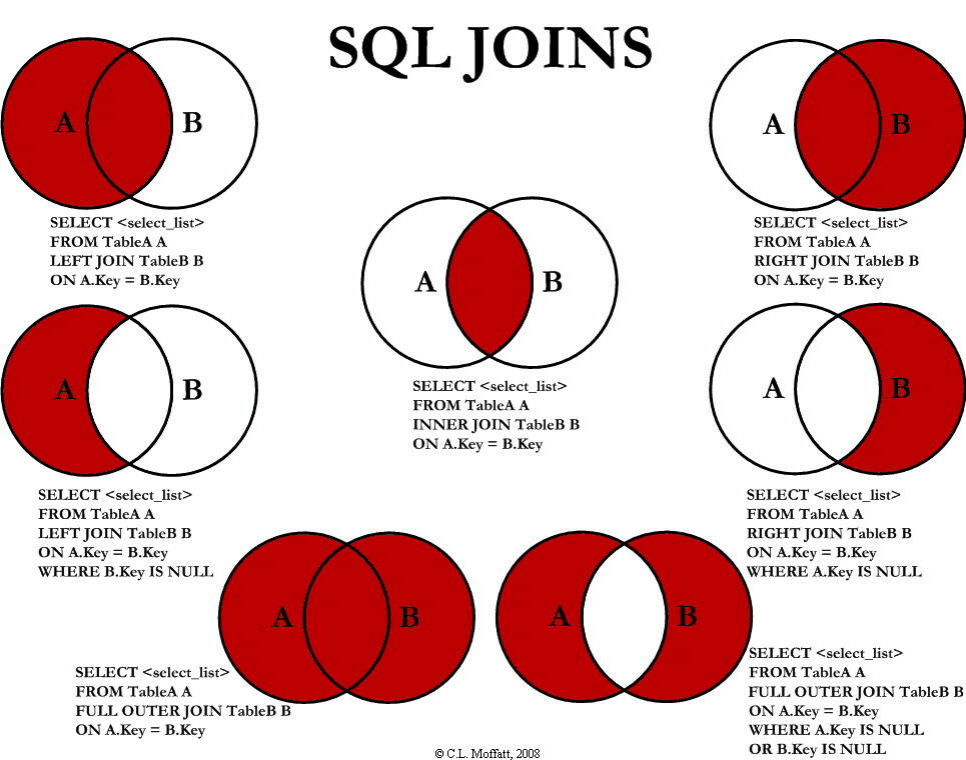
例如我们希望查看在选课记录中查看成绩的同时显示学生的名字:
| SELECT Students.name, course_id, grade
FROM Students
INNER JOIN Association
ON Students.id = student_id AND NOT ISNULL(grade);
|
利用 Sub Query 同时显示课程名和学分,并按学生姓名排序:
| SELECT StuWithCouseID.name student, Courses.title, Courses.credit, StuWithCouseID.grade
FROM Courses
INNER JOIN (
SELECT Students.name, course_id, grade
FROM Students
INNER JOIN Association
ON Students.id = student_id AND NOT ISNULL(grade)
) StuWithCouseID
ON Courses.id = StuWithCouseID.course_id
ORDER BY Student;
|
INNER JOIN 给出了两张表在指定字段交集上的笛卡尔积,用某些关键字将表衔接起来,你可以认为 INNER JOIN 等价于:
| results = []
for record1 in TABLE1:
for record2 in TABLE2:
if P(record1, record2):
results += [record1.concat(record2)]
return result
|
也就是选出两张表笛卡尔积中符合谓词 P 的记录集合,数据库在执行时并不是这样实现的。
因此上面的 INNER JOIN 可以隐式表达为:
| SELECT Students.name, course_id, grade
FROM Students, Association
WHERE Students.id = Association.student_id AND NOT ISNULL(Association.grade);
|
| SELECT Students.name student, Courses.title, Courses.credit, Association.grade
FROM Students, Courses, Association
WHERE Students.id = Association.student_id AND Courses.id = Association.course_id AND NOT ISNULL(Association.grade)
ORDER BY student;
|
对于 INNER JOIN,我们可以认为其与 WHERE = 获得的结果一样,但实现原理却并不相同,JOIN 时使用 hashtable 进行比较,而 WHERE = 则是取笛卡尔积再过滤(即上述 Python 表示的代码)。因此前者效率为 \mathrm{O}(\log \mathrm{N}),后者的效率为 \mathrm{O}(N^2)
除了 INNER JOIN 外还有其他的 JOIN 方式,例如我们想看看每位同学都选了几门课,于是写了这样的查询:
| SELECT Students.sid, COUNT(Association.student_id)
FROM Students
INNER JOIN Association
ON Students.id = Association.student_id
GROUP BY Students.id;
|
结果发现第 50 名同学选了 0 门课并没有返回。这是因为 INNER JOIN 只返回至少存在一个匹配的记录。此时我们可以使用 LEFT JOIN,即无论是否存在匹配,都显示左侧表中的全部记录。对于不存在对应右表记录的左表记录,填充 NULL:
| SELECT Students.sid, COUNT(Association.student_id)
FROM Students
LEFT JOIN Association
ON Students.id = Association.student_id
GROUP BY Students.id;
|
这样就会显示全部学生。
5.2.11 Functions
作为一门(编程)语言,MySQL 提供了 极为丰富的函数库,下面举几个字符串函数的例子。
5.2.11.1 SUBSTRING
查看姓名从第 1 个字符开始的 3 个字符:
| SELECT SUBSTRING(name, 1, 3) FROM Students;
|
5.2.11.2 CHAR_LENGTH
看看谁的名字比较长:
| SELECT CHAR_LENGTH(name) name_len, name
FROM Students
ORDER BY name_len DESC
LIMIT 10;
|
5.2.11.3 REPLACE
对字符串进行替换,比如我认为 Logic 是敏感词,在查询时将其替换为 **:
| SELECT cid, REPLACE(title, 'Logic', '**') FROM Courses;
|
5.3 UPDATE
1
2
3
4
5
6
7
8
9
10
11
12
13
14 | UPDATE [LOW_PRIORITY] [IGNORE] table_reference
SET assignment_list
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count]
value:
{expr | DEFAULT}
assignment:
col_name = value
assignment_list:
assignment [, assignment] ...
|
例如我要更新 History of Musical Theater 课程的学分:
| UPDATE Courses SET credit = 3 WHERE title = 'History of Musical Theater';
|
UPDATE 过程中可以直接使用表中的值:
| UPDATE Courses SET credit = credit + 1 WHERE title = 'History of Musical Theater';
|
5.4 DELETE
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | -- Single-Table Syntax
DELETE [LOW_PRIORITY] [QUICK] [IGNORE] FROM tbl_name [[AS] tbl_alias]
[PARTITION (partition_name [, partition_name] ...)]
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count]
-- Multiple-Table Syntax
DELETE [LOW_PRIORITY] [QUICK] [IGNORE]
tbl_name[.*] [, tbl_name[.*]] ...
FROM table_references
[WHERE where_condition]
DELETE [LOW_PRIORITY] [QUICK] [IGNORE]
FROM tbl_name[.*] [, tbl_name[.*]] ...
USING table_references
[WHERE where_condition]
|
删除 History of Musical Theater 课程的选课记录:
| DELETE Association
FROM Association, Courses
WHERE Association.course_id = Courses.id AND Courses.title = 'History of Musical Theater';
|
在多表删除中,只有 DELETE 和 FROM 之间列举的表中的记录会被删除,FROM 后出现但是不再 DELETE 和 FROM 之间的表仅用作查询的参考。
值得注意的是删除并不会立即释放磁盘空间:
| SHOW TABLE STATUS LIKE 'Association';
|
其中 Data_length 为数据文件的大小(以字节为单位),Index_length 为索引文件的大小(以字节为单位),Data_length + Index_length 表示表的总大小。
我们删除一些数据:
在此查询,发现即使 Association 空了,但是表的大小没有发生变化,为了释放空间,我们可以使用:
| OPTIMIZE TABLE Association;
-- or
ANALYZE TABLE Association;
|
6. EXPLAIN
你可能关心查询是如何被数据库执行的,这是可以使用 EXPLAIN ANALYZE,让 MySQL 打印执行计划,例如:
| EXPLAIN ANALYZE
SELECT Students.sid, COUNT(Association.student_id)
FROM Students
LEFT JOIN Association
ON Students.id = Association.student_id
GROUP BY Students.id;
|
7. SQL Contraints
我们在前面看到的 NOT NULL, UNIQUE, PRIMARY KEY, FOREIGN KEY 等均为约束,用于对字段指定数据规则。
UNIQUE 不只可以约束一列,也可以约束多列(联合唯一);DEFAULT 约束可以用于指定默认值,用于插入时没有指定值得情况;
四、在 Python 中使用 MySQL
若您尚未学习 Python 语言,可暂时跳过本模块
1. PyMySQL
1.1 Example
可以使用 PyMySQL 与 MySQL 数据库进行连接,如 PyMySQL 0.7.2 documentation 中的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26 | import pymysql.cursors
# Connect to the database
connection = pymysql.connect(host='localhost',
user='user',
password='passwd',
database='db',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
with connection:
with connection.cursor() as cursor:
# Create a new record
sql = "INSERT INTO `users` (`email`, `password`) VALUES (%s, %s)"
cursor.execute(sql, ('webmaster@python.org', 'very-secret'))
# connection is not autocommit by default. So you must commit to save
# your changes.
connection.commit()
with connection.cursor() as cursor:
# Read a single record
sql = "SELECT `id`, `password` FROM `users` WHERE `email`=%s"
cursor.execute(sql, ('webmaster@python.org',))
result = cursor.fetchone()
print(result)
|
这样的查询会返回如下格式:
| {'id': 1, 'password': 'very-secret'}
|
1.2 Previous Query
可以使用如下语句来返回上一条执行的 SQL 语句:
在某些 cursor.execute 执行失败的情况下,该值也可能不存在。
1.3 Different Cursor
如果要使用一个默认 Cursor 之外的 Cursor,也可以在执行时指定:
| with conn.cursor(sql.cursors.DictCursor) as cur:
cur.execute(f"SELECT * FROM `video_info` WHERE author=%s;", ("alice",))
res = cur.fetchall()
|
DictCursor 会将查询结果以 dict 形式返回,使用起来较方便。
1.4 Get the value of AUTO INCREMENT
1.5 Cursor Operation
对于记录取用,我们通常使用带缓存的 Curesor(默认)。Cursor 可以看作是记录中的一个指针,这里不妨直接看 PyMySQL 的源码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42 | def fetchone(self):
"""Fetch the next row"""
self._check_executed()
if self._rows is None or self.rownumber >= len(self._rows):
return None
result = self._rows[self.rownumber]
self.rownumber += 1
return result
def fetchmany(self, size=None):
"""Fetch several rows"""
self._check_executed()
if self._rows is None:
return ()
end = self.rownumber + (size or self.arraysize)
result = self._rows[self.rownumber : end]
self.rownumber = min(end, len(self._rows))
return result
def fetchall(self):
"""Fetch all the rows"""
self._check_executed()
if self._rows is None:
return ()
if self.rownumber:
result = self._rows[self.rownumber :]
else:
result = self._rows
self.rownumber = len(self._rows)
return result
def scroll(self, value, mode="relative"):
self._check_executed()
if mode == "relative":
r = self.rownumber + value
elif mode == "absolute":
r = value
else:
raise err.ProgrammingError("unknown scroll mode %s" % mode)
if not (0 <= r < len(self._rows)):
raise IndexError("out of range")
self.rownumber = r
|
1.6 SQL Injection
SQL 注入攻击是指攻击者在 web 应用程序中事先定义好的查询语句结尾上添加额外的恶意 SQL 语句。例如某程序中使用如下代码来判断用户输入的用户名密码是否正确:
| # 用户登录
def login_user(username, password):
db = connect_db()
get_user_query = f"SELECT * FROM users WHERE username = '{username}' AND password = '{password}';"
user = db.cursor().execute(get_user_query).fetchone()
return user is not None
|
正常情况下,我们输入错误密码时无法登录。然而由于 -- 在 SQL 语句中表示注释,则当我们知道希望登录用户的用户名时,可以输入 username="admin' --" && password="Any",上述 SQL 语句便成为了:
| SELECT * FROM users WHERE username = 'admin' --' AND password = 'Any';
|
实际上,我们不需要知道数据库中有哪些用户名,可以输入 username="any' or 1=1 --" && password="Any",上述 SQL 语句便成为了:
| SELECT * FROM users WHERE username = 'any' or 1=1 --' AND password = 'Any';
|
再甚,用户还可以直接删库,供读者自行尝试(Tip:分号表示一条语句的结束,可以跟其他 SQL 语句)。
因此,正确地使用 PyMySQL 会为你的输入进行自动转义,上述查询应写成这样:
| # 用户登录
def login_user(username, password):
db = connect_db()
get_user_query = f"SELECT * FROM users WHERE username = %s AND password = %s;"
user = db.cursor().execute(get_user_query, (username, password)).fetchone()
return user is not None
|
上面两条输入便会对应到:
| SELECT * FROM users WHERE username = 'admin\' --' AND password = 'Any';
SELECT * FROM users WHERE username = 'any\' or 1=1 --' AND password = 'Any';
|
就变得人畜无害咯咯咯~
2. ORM
具体操作我们会在 Django 课程中讲到,在此仅作了解即可。
在我们实际开发中,通常会直接使用成熟的后端框架来操作数据库,例如 Django 等,在这些框架中,你无需手写 SQL 语句,而可以直接使用它的 ORM 框架(或者其他框架)。
ORM 全称为 Objected Relational Mapping,其构造了数据库对象与 Python 对象中的如下映射:
| TABLE -> Class
Record -> Instance(实例)
Column -> Attribute(属性)
|
实际上,ORM 在执行操作时依然会将对应的操作转换成数据库原生语句,但是其拥有如下优点:

五、参考资料
最后更新:
2023年7月15日